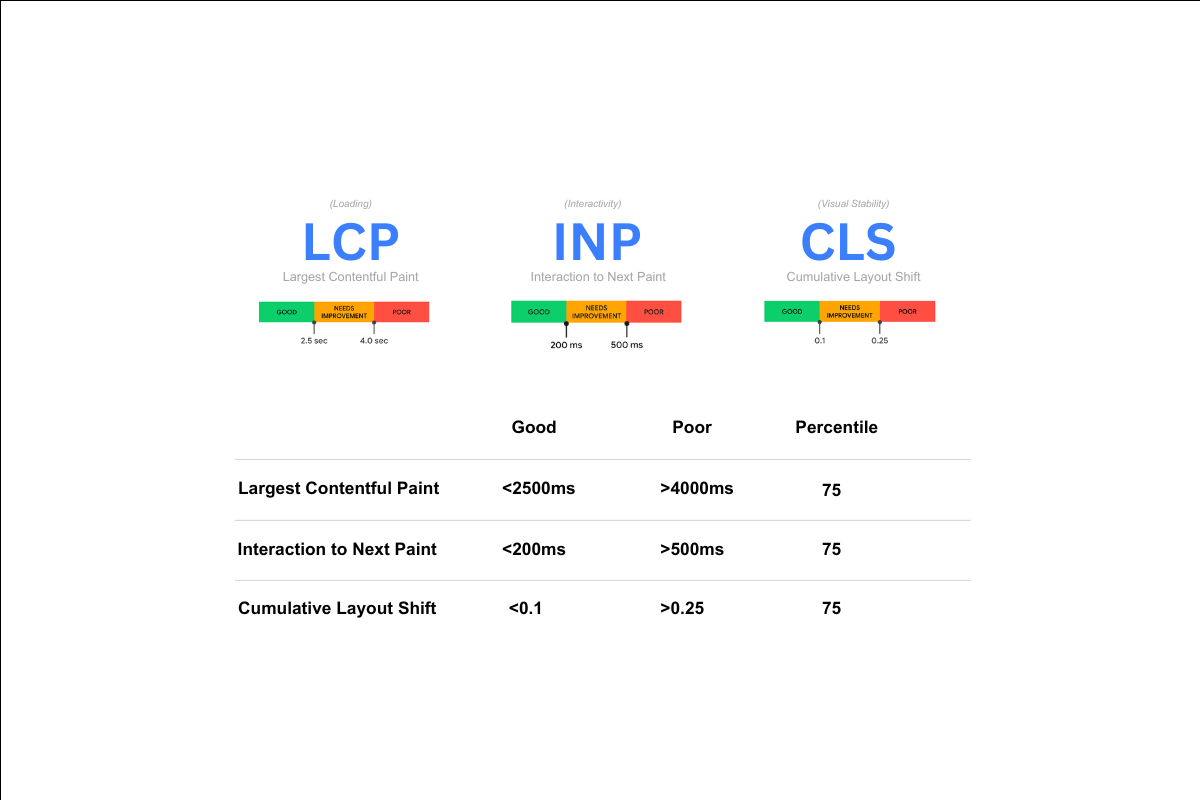
El SEO técnico ya no termina cuando Googlebot puede rastrear e indexar tu sitio. En 2026, hay una segunda capa de visibilidad que determina si los agentes de inteligencia artificial pueden acceder a tu contenido, extraerlo y usarlo para generar respuestas.
Esa capa tiene sus propias reglas. Y la mayoría de los sitios todavía no la está trabajando.
Por qué los agentes de IA rastrean diferente a Googlebot
Los motores de búsqueda tradicionales rastrean para indexar — guardan una copia de tu página para mostrarla en resultados futuros. Los agentes de IA, en cambio, rastrean para sintetizar: acceden a tu contenido en tiempo real para construir una respuesta, extraen la información relevante y la combinan con otras fuentes.
Esto tiene consecuencias técnicas concretas. Un agente de IA que encuentra una página con JavaScript pesado, contenido detrás de login, o estructura de encabezados confusa va a tener dificultades para extraer información útil — y va a priorizar otra fuente que le resulte más legible. La accesibilidad técnica ya no es solo para rankear: es la condición de entrada para ser citado.
Robots.txt: la primera decisión que tomar
El archivo robots.txt es la herramienta más directa para controlar qué agentes de IA pueden acceder a tu sitio y qué secciones pueden rastrear. La decisión no es trivial porque implica elegir entre dos objetivos que no siempre van en la misma dirección: entrenamiento de modelos vs. búsqueda en tiempo real y citaciones.
Los principales crawlers de IA tienen user-agents propios que podés controlar de forma independiente:
- GPTBot (OpenAI) — accede para entrenar modelos y para búsquedas en tiempo real de ChatGPT
- Google-Extended — controla el acceso de Google para entrenar sus modelos de IA, separado del rastreo de Search
- PerplexityBot — crawler de Perplexity para sus respuestas generativas
- ClaudeBot (Anthropic) — crawler de Claude para entrenamiento y respuestas
- Amazonbot — usado por Alexa y los sistemas de IA de Amazon
Una configuración razonable para un medio digital o empresa que quiere aparecer en respuestas de IA sin ceder todo su contenido para entrenamiento podría ser:
User-agent: GPTBot
Allow: /noticias/
Allow: /blog/
Disallow: /privado/
User-agent: Google-Extended
Disallow: /En este ejemplo se permite que GPTBot acceda al contenido editorial pero se bloquea Google-Extended para que no use ese contenido en el entrenamiento de Gemini. Cada organización debe tomar esta decisión según su política editorial y sus objetivos de visibilidad.
Schema markup: de los rich snippets a la legibilidad para IA
El schema markup tuvo durante años un objetivo claro: conseguir rich snippets en Google. En 2026 ese objetivo sigue vigente, pero apareció uno nuevo: hacer que tu contenido sea interpretable por los sistemas de IA que generan respuestas.
Los tipos de schema más relevantes para visibilidad en búsqueda generativa son:
Organization con sameAs
Conecta tu sitio a entidades verificables externas como Wikipedia, LinkedIn, Crunchbase o Wikidata. Cuando un agente de IA encuentra tu sitio y puede correlacionarlo con entidades en otras fuentes confiables, la señal de autoridad se multiplica. Es la base del entity SEO aplicado a la IA.
FAQPage y HowTo
El formato pregunta-respuesta es exactamente lo que los modelos buscan para sintetizar respuestas directas. Una página con schema FAQPage correctamente implementado le dice al agente: “acá hay preguntas y respuestas listas para extraer”. Es uno de los tipos de schema con mayor correlación con apariciones en AI Overviews.
Article y NewsArticle
Fundamental para medios digitales. Declara autor, fecha, imagen y cuerpo del artículo de forma estructurada. Los sistemas de IA usan esta información para validar la frescura y la autoría del contenido — dos señales que pesan mucho en la selección de fuentes para respuestas generativas. Podés ver más sobre esto en nuestra guía de schema markup para IA en 2026.
SignificantLink
Un tipo de schema más reciente que permite señalarle a los agentes cuáles son los pilares de contenido más importantes de tu sitio. Funciona como una jerarquía editorial explícita: en lugar de que el modelo infiera qué página es la más relevante de un tema, vos se lo decís directamente.
Estructura de contenido: cómo escribir para que la IA pueda extraer
Los agentes de IA no leen una página de la misma forma que un humano. Escanean en busca de unidades de información extractables: respuestas directas a preguntas, definiciones, listas, datos concretos. El contenido que responde claramente en el primer párrafo después de un encabezado tiene más chances de ser citado que el que llega a la respuesta después de tres párrafos de contexto.
Algunas reglas prácticas para estructurar contenido pensado para extracción por IA:
- Respondé la pregunta principal en las primeras dos líneas del H2. Lo que no aparece pronto, en la mayoría de los casos no aparece.
- Usá encabezados en formato pregunta para las secciones principales. Los agentes los interpretan como señales de que hay una respuesta directa debajo.
- Preferí listas y tablas sobre párrafos densos para información comparativa o enumerativa.
- Evitá el contenido renderizado con JavaScript para información crítica. El 46% de las visitas de agentes de IA comienza en modo lectura sin CSS ni scripts — si tu contenido depende de JS para mostrarse, puede no ser accesible.
- Asegurate de que el HTML sea semánticamente correcto. H1 único, jerarquía H2/H3 coherente, texto alternativo en imágenes.
Rendimiento técnico: velocidad y frescura
Los agentes de IA son especialmente sensibles a dos factores técnicos que a veces se subestiman: la velocidad de respuesta del servidor y la frescura del contenido.
Un TTFB alto (Time To First Byte) hace que muchos agentes abandonen antes de terminar de cargar la página. Si el servidor tarda más de 800ms en responder, el agente puede marcar ese recurso como poco confiable y pasar al siguiente. Esto tiene implicaciones directas para el crawl budget y la gestión del rastreo.
La frescura importa porque los sistemas de IA son más exigentes con el contenido desactualizado que el algoritmo de Google tradicional. Un benchmark del año pasado, una definición que no fue revisada en dos años o estadísticas desactualizadas son señales que reducen la probabilidad de selección. Los modelos quieren la versión más actualizada de la información disponible.
El SEO técnico como infraestructura de visibilidad en IA
La diferencia entre el SEO técnico tradicional y el SEO técnico para IA no es de herramientas — es de objetivo. Antes se optimizaba para que Googlebot pudiera rastrear e indexar. Ahora se optimiza para que múltiples agentes de distintos sistemas puedan acceder, interpretar y reutilizar el contenido.
Los sitios que ya tienen una base técnica sólida tienen ventaja: buena velocidad, HTML limpio, schema implementado, arquitectura clara. Lo que necesitan es dar el paso siguiente: auditar esa base con los ojos de un agente de IA, no solo con los de Googlebot.
Para entender cómo esto se conecta con los KPIs SEO que realmente importan en 2026, el panorama se completa bastante. La visibilidad en IA ya es una métrica que hay que medir por separado — y la infraestructura técnica es lo que la hace posible.
Si querés trabajar tu estrategia SEO con acompañamiento experto, podés conocer cómo trabajamos en nuestra consultoría SEO.